 Inglês
Inglês  Chinês
Chinês  Alemão
Alemão  Coreano
Coreano  Japonês
Japonês  Farsi
Farsi  Portuguese
Portuguese  Russian
Russian  Espanhol
Espanhol 

Computer vision is one of the most popular research areas in the field of deep learning. It is located at the intersection of many academic subjects, such as computer science (graphics, algorithms, theory, systems, architecture), mathematics (information retrieval, machine learning), engineering (robotics, speech, natural language processing, image processing), Physics (optics), biology (neuroscience) and psychology (cognitive science). Since computer vision represents a relative understanding of the visual environment and its context, many scientists believe that the field paves the way for artificial intelligence because of its cross-domain mastery.
So what is computer vision? Here are some official textbook definitions:
“Building clear, meaningful physical object descriptions from images” (Ballard & Brown, 1982)
"Calculating the properties of a 3D world from one or more digital images" (Trucco & Verri, 1998)
“Make useful decisions about real objects and scenes based on perceived images” (Sockman & Shapiro, 2001)
Why study computer vision? The most obvious answer is a collection of rapidly growing useful applications derived from this area of research. Here is a small part of it:
Face Recognition: Snapchat and Facebook use the Face Detection algorithm to apply a convolution kernel and identify you in the image.
Image Retrieval: Google Images uses content-based queries to search for related images. The algorithm analyzes the content in the query image and returns the result based on the best match.
Game and Control: Microsoft Kinect is a great commercial product in a game that uses stereo vision.
Surveillance: Surveillance cameras are ubiquitous in public places and are used to detect suspicious behavior.
Biometrics: Fingerprint, iris and face matching are still some of the common methods used in biometrics.
Smart cars: Vision is still the primary source of information for detecting traffic signs and lights and other visual features.
I recently completed Stanford University's exciting CS231n course on visual recognition using convolutional neural networks. Visual recognition tasks such as image classification, location and detection are key components of computer vision. Recent developments in neural networks and deep learning methods have greatly improved the performance of these state of the art visual recognition systems. This course is an extraordinary resource that teaches me the details of using a deep learning architecture in top computer vision research. In this article, I want to share the five main computer vision techniques I have learned, as well as the main deep learning models and applications that use each technology.
1--image classification

The problem with image classification is this: Given a set of images of a single category of annotations, we are required to predict these categories for a new set of test sets and test the accuracy of the predictions. There are many challenges with this task, including viewpoint changes, scale changes, intra-class changes, image distortion, image occlusion, conditions, and cluttered backgrounds.
How do we write an algorithm that can divide images into different categories? Computer vision researchers have proposed a data-driven approach to solve this problem. Instead of trying to specify each image category of interest directly in the code, they provide the computer with many samples of each image class, then develop learning algorithms, view the samples and understand the visual appearance of each class. In other words, they first collect a training set with an annotated image and then pass it to the computer to process the data.
Given this fact, the entire image classification process can be formalized as follows:
Our input is a training set that includes N images, each of which is labeled with K different categories.
Then, we use this training set to train the classifier to understand what each category looks like.
Finally, we evaluate the effect of the classifier by having this classifier predict a new set of images that it has not seen before. We then compare the real labels of these images with those predicted by the classifier.
Convolutional neural networks (CNNs) are the most popular architecture for image classification. A typical use case for CNNs is that you pass this network image, and then the network classifies the data. CNNs often start with the input "scanner" and it is not intended to parse all training data at once. For example, to enter a 100 x 100 pixel image, you don't need a layer with 10,000 nodes. Instead, you'll create a 10×10 scan input layer that you can provide for the first 10×10 pixels of the image. After this input, the next 10 × 10 pixels can be input by moving the scanner one pixel to the right. This technique is called a sliding window.
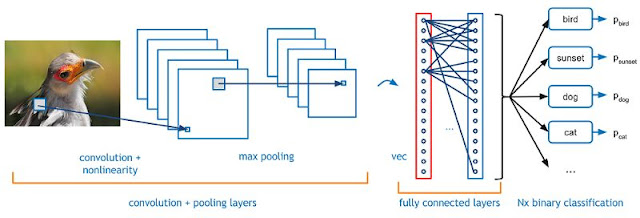
The input data is then fed through the convolutional layer instead of the normal layer. Each node only focuses on the part that is adjacent to itself. These convolutional layers tend to shrink as the network deepens, mainly through the easy decomposition of input. In addition to convolutional layers, they usually have a feature pooling layer. Pooling is a way to filter details: the common pooling technique is maximum pooling, we use 2 x 2 pixels and pass the pixels with the largest amount of specific properties.
At present, most image classification techniques are trained on ImageNet, which is a data set of about 1.2 million high-resolution training images. The test image does not display the initial comment (no split or label), and the algorithm must generate a label that specifies the object that exists in the image. The leading computer vision teams at Oxford, INRIA, XRCE and others use the best computer vision methods available for this data set. Often, computer vision systems are complex, multi-level systems that often require manual tuning to optimize parameters at an early stage.
The winner of the first ImageNet competition Alex Krizhevsky (NIPS 2012) The deep convolutional neural network pioneered by Yann LeCun. Its structure includes 7 hidden layers, excluding some of the largest pooling layers. The first 5 layers are convolutional layers and the last 2 layers are fully connected layers. The activation function for each hidden layer is ReLU. These trainings are faster and more expressive than logic units. In addition, when similar units have stronger activation values, it also uses competitive normalization to suppress hidden activity. This contributes to changes in strength.

In terms of hardware requirements, Alex used a very efficient convolutional network implementation on two Nvidia GTX 580 GPUs (more than 1000 fast small cores). The GPU is well suited for matrix matrix multiplication and has a very high memory bandwidth. This allowed him to train the network within a week and quickly combine the results of 10 patches during the test. If we can communicate state quickly enough, we can spread the network across multiple cores. As cores become cheaper and data sets grow larger, large neural networks will improve faster than older computer vision systems. Since AlexNet, a number of new models have used CNN as their backbone architecture and have achieved outstanding results in ImageNet: ZFNet (2013), GoogLeNet (2014), VGGNet (2014), ResNet (2015), DenseNet (2016) )Wait.
to be continued
Follow Me
linkedin:https://www.linkedin.com/in/nicole-song-64400b147/





